
HTTP est un protocole de transmission au même titre que FTP.
Il permet à un client de récupérer auprès d’un serveur web des données. Si le client est un navigateur web, ce protocole permet d’obtenir les données nécessaires à l’affichage d’une page internet.

Le protocole fonctionne par l’intermédiaire de requêtes émises par le client et de réponses fournies par le serveur.
Nous pouvons consulter les requêtes (et les réponses) HTML avec le navigateur Firefox avec le developpement web.
Examinons la demande d’une page web telle que mathartung.xyz/nsi par un navigateur internet.
Le navigateur commence par demander, à un serveur de noms de domaines (DNS), l’adresse IP de mathartung.xyz.
Celui-ci lui fournit 185.28.20.156.
La communication par IP n’est pas suffisante car sur un ordinateur peuvent fonctionner diverses applications utilisant internet comme un navigateur ou un logiciel de messagerie. De plus, les paquets de données transitant par le protocole IP ont une taille limite d’environ 1500 octets.
On utilise alors TCP, un protocole de connexion situé sur une couche supérieure à celle d’IP :
Le navigateur contacte donc directement le serveur web à l’adresse 185.28.20.156 :80 en utilisant la couche TCP/IP. La connexion s’établit grâce au 3way-handshake.
Le client envoie alors la requête HTTP au serveur web :

La requête possède toujours la même forme :
Le serveur web renvoie l’entête suivant :
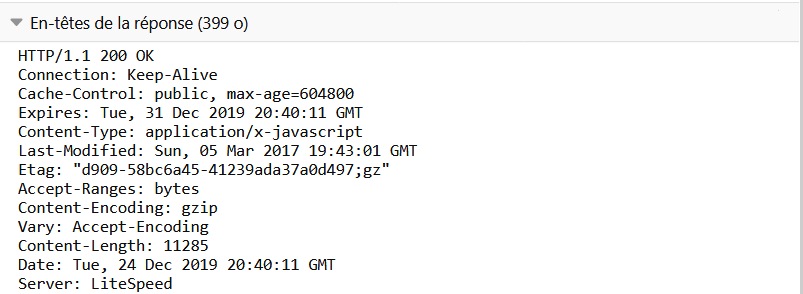
suivi des données c’est-à-dire de la page web au format HTML.
La réponse possède, elle aussi, une réponse formatée :
Le navigateur analyse la page et, pour chaque lien présent, réalise toutes les étapes précédentes avant d’afficher le résultat. Une
page web moderne peut nécessiter près de 100 requêtes : la page mathartung.xyz/nsi a nécessité par exemple 24 requêtes.
L’étude des requêtes et des réponses HTTP peut être réalisée dans Firefox grâce au menu Outils/Développement web/Réseau. Les méthodes disponibles pour HTTP sont les suivantes : GET, HEAD, POST, PUT, DELETE, CONNECT, OPTIONS, TRACE, PATCH. GET permet d’obtenir une ressource.
PUT, DELETE et PATCH permettent de modifier des données sur le serveur : il est évidemment nécessaire d’être authentifié pour réaliser ces changements et le serveur doit être configuré pour autoriser ces changements. HEAD permet d’obtenir seulement l’en-tête de la réponse. POST permet d’envoyer une ressource au serveur : cette méthode est souvent utilisée lors du remplissage d’un formulaire. Les codes de statuts commencent par 100, 200, 300, 400 ou 500.
| Code | Message | Description |
|---|---|---|
| 10x | Message d'information | Ces codes ne sont pas utilisés dans la version 1.0 du protocole |
| 20x | Réussite | Ces codes indiquent le bon déroulement de la transaction |
| 200 | OK | La requête a été accomplie correctement |
| 201 | CREATED | Elle suit une commande POST, elle indique la réussite, le corps du reste du document est sensé indiquer l'URL à laquelle le document nouvellement créé devrait se trouver. |
| 202 | ACCEPTED | La requête a été acceptée, mais la procédure qui suit n'a pas été accomplie |
| 203 | PARTIAL INFORMATION | Lorsque ce code est reçu en réponse à une commande GET, cela indique que la réponse n'est pas complète. |
| 204 | NO RESPONSE | Le serveur a reçu la requête mais il n'y a pas d'information à renvoyer |
| 205 | RESET CONTENT | Le serveur indique au navigateur de supprimer le contenu des champs d'un formulaire |
| 206 | PARTIAL CONTENT | Il s'agit d'une réponse à une requête comportant l'en-tête range. Le serveur doit indiquer l'en-tête content-Range |
| 30x | Redirection | Ces codes indiquent que la ressource n'est plus à l'emplacement indiqué |
| 301 | MOVED | Les données demandées ont été transférées à une nouvelle adresse |
| 302 | FOUND | Les données demandées sont à une nouvelle URL, mais ont cependant peut-être été déplacées depuis... |
| 303 | METHOD | Cela implique que le client doit essayer une nouvelle adresse, en essayant de préférence une autre méthode que GET |
| 304 | NOT MODIFIED | Si le client a effectué une commande GET conditionnelle (en demandant si le document a été modifié depuis la dernière fois) et que le document n'a pas été modifié il renvoie ce code. |
| 40x | Erreur due au client | Ces codes indiquent que la requête est incorrecte |
| 400 | BAD REQUEST | La syntaxe de la requête est mal formulée ou est impossible à satisfaire |
| 401 | UNAUTHORIZED | Le paramètre du message donne les spécifications des formes d'autorisation acceptables. Le client doit reformuler sa requête avec les bonnes données d'autorisation |
| 402 | PAYMENT REQUIRED | Le client doit reformuler sa demande avec les bonnes données de paiement |
| 403 | FORBIDDEN | L'accès à la ressource est tout simplement interdit |
| 404 | NOT FOUND | Classique! Le serveur n'a rien trouvé à l'adresse spécifiée. Parti sans laisser d'adresse... :) |
| 50x | Erreur due au serveur | Ces codes indiquent qu'il y a eu une erreur interne du serveur |
| 500 | INTERNAL ERROR | Le serveur a rencontré une condition inattendue qui l'a empêché de donner suite à la demande (comme quoi il leur en arrive des trucs aux serveurs...) |
| 501 | NOT IMPLEMENTED | Le serveur ne supporte pas le service demandé (on ne peut pas tout savoir faire...) |
| 502 | BAD GATEWAY | Le serveur a reçu une réponse invalide de la part du serveur auquel il essayait d'accéder en agissant comme une passerelle ou un proxy |
| 503 | SERVICE UNAVAILABLE | Le serveur ne peut pas vous répondre à l'instant présent, car le trafic est trop dense (toutes les lignes de votre correspondant sont occupées veuillez rappeler ultérieurement) |
| 504 | GATEWAY TIMEOUT | La réponse du serveur a été trop longue vis-à-vis du temps pendant lequel la passerelle était préparée à l'attendre (le temps qui vous était imparti est maintenant écoulé...) |
HTTP est sans état, c’est-à-dire qu’il n’y a pas de lien entre deux requêtes réalisées sur la même connexion. Cela pose problème en particulier sur des sites de commerce en ligne avec un panier d’achat que l’on remplit au fur et à mesure. Mais HTTP n’est pas sans session : on ajoute des cookies au flux HTTP, que l’on stocke sur le client, ce qui permet de maintenir une session pour l’utilisateur et donc de remplir le panier d’achat !
HTTP a connu plusieurs révisions :
Ces révisions permettent d’accélérer le chargement des pages web qui ont une certaine tendance à l’embonpoint ! De plus, les données sont mises en cache dans le navigateur. Cela permet de ne pas les recharger auprès du serveur lorsque l’on utilise les boutons Précédent et Suivant du navigateur.