Le codage des informations
Qu'est-ce que le code ASCII ?
La mémoire de l'ordinateur conserve toutes les données sous forme numérique Il n'existe pas de méthode
pour stocker directement les caractères. Chaque caractère possède donc son équivalent en code numérique : c'est le
code ASCII 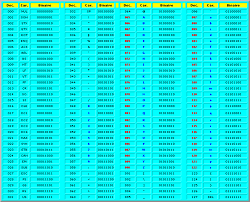 (American Standard Code for Information Interchange - traduisez ''Code Americain Standard pour l'Echange d'Informations'').
(American Standard Code for Information Interchange - traduisez ''Code Americain Standard pour l'Echange d'Informations'').
Cliquez sur l'image pour agrandir
Table des caractères ASCII EtendueLe code ASCII a été mis au point pour la langue anglaise, il ne contient donc pas de caractères
accentués, ni de caractères spécifiques à une langue. Pour coder ce type de caractère il faut recourir à
un autre code. Le code ASCII a donc été étendu à 8 bits (un octet) pour pouvoir coder plus de caractères
(on parle d'ailleurs de code ASCII étendu...).
Ce code attribue les valeurs 0 à 255 (donc codées sur 8 bits, soit 1 octet) aux lettres
majuscules et minuscules, aux chiffres, aux marques de ponctuation et aux autres symboles (caractères accentués dans le cas du code
iso-latin1).
Le code ASCII étendu n'est donc pas unique et dépend fortement de la plateforme utilisée.
Les deux jeux de caractères ASCII étendus les plus couramment utilisés sont :


Vous avez toujours pas compris? Ou vous êtes juste fainéant? Ce convertisseur est fait pour vous! Grâce à ce dernier, jonglez
entre texte, décimal, binaire ou héxadécimal!
Texte*
Décimal
Binaire
Héxadécimal (code ASCII étendu ANSI)
*Les caractères de contrôle ne vont pas être représentés sous forme de texte. Ce convertisseur ne concerne que l'ASCII.
Le code Unicode est un système de codage des caractères sur 16 bits mis au point en 1991. Le système Unicode permet de représenter n'importe quel caractère par un code sur 16 bits, indépendamment de tout système d'exploitation ou langage de programmation. Au lieu d'utiliser seulement les codes 0 à 127, il utilise des codes de valeur bien plus grandes.

Le code UNICODE permet de représenter tous les caractères spécifiques aux différentes langues. De nouveaux codes sont régulièrement attribués pour de nouveaux caractères: caractères latins (accentués ou non), grecs, cyrillics, arméniens, hébreux, thaï, hiragana, katakana... L'alphabet Chinois Kanji comporte à lui seul 6879 caractères.Il regroupe ainsi la quasi-totalité des alphabets existants (arabe, arménien, cyrillique, grec, hébreu, latin, ...) et est compatible avec le code ASCII.
L'Unicode définie donc un correspondance entre symboles et nombres.
Même si l'UNICODE est bien conçu, il reste assez peu utilisé par rapport à l'ASCII. (Ne vous amusez pas à envoyer un message en UNICODE à quelqu'un : il ne saurait probablement pas comment le lire !). Pour les programmeurs, ça n'est pas toujours très facile à manipuler non plus.
L'ensemble des codes Unicode est disponible sur le site http://www.unicode.org.
Unicode, dans la théorie, c'est très bien.
Mais dans la pratique, c'est une autre paire de manches:
 Généralement en Unicode, un caractères prend 2 octets. Autrement dit, le moindre texte prend deux fois plus de place qu'en ASCII. C'est du
gaspillage.
Généralement en Unicode, un caractères prend 2 octets. Autrement dit, le moindre texte prend deux fois plus de place qu'en ASCII. C'est du
gaspillage.
De plus, si on prend un texte en français, la grande majorité des caractères utilisent seulement le code ASCII. Seuls quelques rares caractères nécessitent l'Unicode.
On a donc trouvé une astuce: l'UTF-8.
Un texte en UTF-8 est simple: il est partout en ASCII, et dès qu'on a besoin d'un caractère appartenant à l'Unicode, on utilise un caractère spécial signalant "attention, le caractère suivant est en Unicode".
Par exemple, pour le texte "Bienvenue chez Sébastien !", seul le "é" ne fait pas partie du code ASCII. On écrit donc en UTF-8:
![]()
Pour être rigoureux, on indique quand même au début du fichier que c'est un fichier en UTF-8 à l'aide de caractères spéciaux:
![]()
L'UTF-8 rassemble le meilleur de deux mondes: l'efficacité de l'ASCII et l'étendue de l'Unicode. D'ailleurs l'UTF-8 a été adopté comme norme pour l'encodage des fichiers XML. La plupart des navigateurs récents supportent également l'UTF-8 et le détectent automatiquement dans les pages HTML.
Un entier relatif est un entier pouvant être négatif. Il faut donc 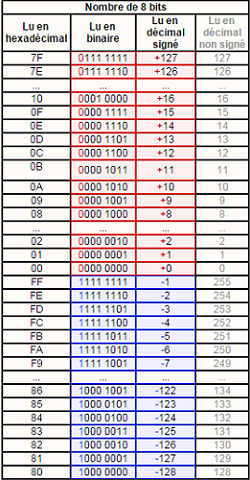 coder le
nombre de telle façon que l'on puisse savoir s'il s'agit d'un nombre positif ou d'un nombre négatif, et il faut de plus que les
règles d'addition soient
conservées. L'astuce consiste à utiliser un codage que l'on appelle complément à deux.
Un entier relatif positif ou nul sera représenté en binaire (base 2) comme un entier naturel, à la seule différence
que le bit de poids fort (le bit situé à l'extrême gauche) représente le signe. Il faut donc s'assurer pour un entier positif
ou nul qu'il est à zéro (0 correspond à un signe positif, 1 à un signe négatif). Ainsi si on code un entier naturel sur
4 bits, le nombre le plus grand sera 0111 (c'est-à-dire 7 en base décimale).
coder le
nombre de telle façon que l'on puisse savoir s'il s'agit d'un nombre positif ou d'un nombre négatif, et il faut de plus que les
règles d'addition soient
conservées. L'astuce consiste à utiliser un codage que l'on appelle complément à deux.
Un entier relatif positif ou nul sera représenté en binaire (base 2) comme un entier naturel, à la seule différence
que le bit de poids fort (le bit situé à l'extrême gauche) représente le signe. Il faut donc s'assurer pour un entier positif
ou nul qu'il est à zéro (0 correspond à un signe positif, 1 à un signe négatif). Ainsi si on code un entier naturel sur
4 bits, le nombre le plus grand sera 0111 (c'est-à-dire 7 en base décimale).
Principe du complément à deux :
On doit représenter un nombre négatif.
On remarquera qu'en ajoutant le nombre et son complément à deux on obtient 0 (voir les règles d'addition)
Voyons maintenant cela sur un exemple :
On désire coder la valeur -5 sur 8 bits. Il suffit :
Il s'agit d'aller représenter un nombre binaire à virgule (par exemple 101,01 qui ne se lit pas cent
un virgule zéro un puisque c'est un nombre binaire mais 5,25 en décimale) sous la forme 1,XXXXX... * 2^n
(c'est-à-dire dans notre exemple 1,0101*2^2). La norme IEEE définie la façon de coder un nombre réel.
Cette norme se propose de coder le nombre sur 32 bits et définit trois composantes :
Ainsi le codage se fait sous la forme suivante :
seeeeeeeemmmmmmmmmmmmmmmmmmmmmmm
Certaines conditions sont toutefois à respecter pour les exposants :

La formule d'expression des nombres réels est ainsi la suivante:
(-1)^S * 2^( E - 127 ) * ( 1 + F )
où:
Voyons ce codage sur un exemple :
Soit à coder la valeur 525,5.
00000110110000000000000
0 1000 1000 00000110110000000000000
0100 0100 0000 0011 0110 0000 0000 0000 (4403600 en hexadécimal)
Voici un autre exemple avec un réel négatif :
Soit à coder la valeur -0,625.
1 1111 1110 01000000000000000000000
1111 1111 0010 0000 0000 0000 0000 0000 (FF 20 00 00 en hexadécimal)
Si vous mettez directement le caractère "é" dans une page web, ce n'est pas bien. ll faut obligatoirement choisir une des 3 solutions suivantes:
é à la place de "é".é" tel quel et préciser le charset que vous utilisez au début du fichier HTML (dans la balise <head>):<meta http-equiv="Content-type" content="text/html; charset=ISO-8859-1">(ISO-8859-1 est le jeu de caractère latin courant sous Windows.)
<meta http-equiv="Content-type" content="text/html; charset=UTF-8">L'ISO-8859-1 convient pour la plupart des langues latines ou occidentales (anglais, français, allemand, espagnol...), et l'UTF-8 vous sera indispensable pour les autres langues (japonais, hébreu, etc.).
A vous de choisir en fonction de vos besoins.